This blog post has moved to
http://blogs.oracle.com/optimizer/entry/upgrading_from_9i_to_11g_and_the_implicit_migration_from_rbo
Maria Colgan
Monday, December 21, 2009
Tuesday, November 17, 2009
Wednesday, October 28, 2009
Oracle Open World 2009 Summary
We had a great time talking to our users at Open World 2009 both at our Demogrounds booth and at our two sessions. We received a lot of interesting questions during the Optimizer Roundtable discussion, but we did not get to answer all of them due to time constraints. We plan to address the questions we received (both answered and unanswered) in future blog posts... so stay tuned. If you didn't get to attend the discussion, but have a question about the Optimizer, submit it through the email link above.
For those of you who did not get a chance to stop by our Demogrounds booth, here's a recap of the new features that we talked about. Many of the topics have already been covered in earlier blog posts.
Maria Colgan
For those of you who did not get a chance to stop by our Demogrounds booth, here's a recap of the new features that we talked about. Many of the topics have already been covered in earlier blog posts.
- Enhanced bind peeking with Adaptive Cursor Sharing: Read about Adaptive Cursor Sharing and a followup.
- Faster and more accurate Statistics gathering: Read about our new statistics gathering algorithm in 11g and incremental maintenance of global statistics for partitioned tables.
- New types of Statistics that improve cardinality estimates
- Ability to gather but not publish Statistics
- Guaranteed plan stability and controlled plan evolution: Read about SQL Plan Management.
- New tools to help correct regressed execution plans: Read about our Plan Diff tool and Test Case Builder.
Maria Colgan
Friday, October 9, 2009
Open World Recap and New White papers
The Optimizer group has two session and a demo station in the Database campground at this year's Oracle Open World. We will give a technical presentation on What to Expect from the Oracle Optimizer When Upgrading to Oracle Database 11g and host an Oracle Optimizer Roundtable.
The technical session, which is on Tuesday Oct 13 at 2:30 pm, gives step by step instructions on how to use the new 11g features to ensure your upgrade goes smoothly and without any SQL plan regressions. This session is based on our latest white papers, Upgrading from Oracle Database 10g to 11g: What to expect from the Optimizer and SQL Plan Management in Oracle Database 11g.
The roundtable, which is on Thursday Oct. 15th at 10:30 am, will give you a first hand opportunity to pose you burning Optimizer and statistics questions directly to a panel of our leading Optimizer developers. In fact if you plan to attend the roundtable and already know what questions you would like to ask, then please send them to us via email and we will be sure to include them. Other wise, you can hand in your questions at our demo station at any stage during the week, or as you enter the actual session. Just be sure to write your questions in clear block capitals!
We look forward to see you all at Open world.
Maria Colgan
The technical session, which is on Tuesday Oct 13 at 2:30 pm, gives step by step instructions on how to use the new 11g features to ensure your upgrade goes smoothly and without any SQL plan regressions. This session is based on our latest white papers, Upgrading from Oracle Database 10g to 11g: What to expect from the Optimizer and SQL Plan Management in Oracle Database 11g.
The roundtable, which is on Thursday Oct. 15th at 10:30 am, will give you a first hand opportunity to pose you burning Optimizer and statistics questions directly to a panel of our leading Optimizer developers. In fact if you plan to attend the roundtable and already know what questions you would like to ask, then please send them to us via email and we will be sure to include them. Other wise, you can hand in your questions at our demo station at any stage during the week, or as you enter the actual session. Just be sure to write your questions in clear block capitals!
We look forward to see you all at Open world.
Maria Colgan
Tuesday, September 1, 2009
Tuesday, August 11, 2009
Understanding DBMS_STATS.SET_*_PREFS procedures
In previous Database releases you had to use the DBMS_STATS.SET_PARM procedure to change the default value for the parameters used by the DBMS_STATS.GATHER_*_STATS procedures. The scope of any changes that were made was all subsequent operations. In Oracle Database 11g, the DBMS_STATS.SET_PARM procedure has been deprecated and it has been replaced with a set of procedures that allow you to set a preference for each parameter at a table, schema, database, and Global level. These new procedures are called DBMS_STATS.SET_*_PREFS and offer a much finer granularity of control.
However there has been some confusion around which procedure you should use when and what the hierarchy is among these procedures. In this post we hope to clear up the confusion. Lets start by looking at the list of parameters you can change using the DBMS_STAT.SET_*_PREFS procedures.
As mentioned above there are four DBMS_STATS.SET_*_PREFS procedures.
The DBMS_STATS.SET_TABLE_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for the specified table only.
The DBMS_STATS.SET_SCHEMA_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for all of the existing objects in the specified schema. This procedure actually calls DBMS_STATS.SET_TABLE_PREFS for each of the tables in the specified schema. Since it uses DBMS_STATS.SET_TABLE_PREFS calling this procedure will not affect any new objects created after it has been run. New objects will pick up the GLOBAL_PREF values for all parameters.
The DBMS_STATS.SET_DATABASE_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for all of the user defined schemas in the database. This procedure actually calls DBMS_STATS.SET_TABLE_PREFS for each of the tables in each of the user defined schemas. Since it uses DBMS_STATS.SET_TABLE_PREFS this procedure will not affect any new objects created after it has been run. New objects will pick up the GLOBAL_PREF values for all parameters. It is also possible to include the Oracle owned schemas (sys, system, etc) by setting the ADD_SYS parameter to TRUE.
The DBMS_STATS.SET_GLOBAL_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for any object in the database that does not have an existing table preference. All parameters default to the global setting unless there is a table preference set or the parameter is explicitly set in the DBMS_STATS.GATHER_*_STATS command. Changes made by this procedure will affect any new objects created after it has been run as new objects will pick up the GLOBAL_PREF values for all parameters.
With GLOBAL_PREFS it is also possible to set a default value for one additional parameter, called AUTOSTAT_TARGET. This additional parameter controls what objects the automatic statistic gathering job (that runs in the nightly maintenance window) will look after. The possible values for this parameter are ALL,ORACLE, and AUTO. ALL means the automatic statistics gathering job will gather statistics on all objects in the database. ORACLE means that the automatic statistics gathering job will only gather statistics for Oracle owned schemas (sys, sytem, etc) Finally AUTO (the default) means Oracle will decide what objects to gather statistics on. Currently AUTO and ALL behave the same.
In summary, DBMS_STATS obeys the following hierarchy for parameter values, parameters values set in the DBMS_STAT.GATHER*_STATS command over rules everything. If the parameter has not been set in the command we check for a table level preference. If there is no table preference set we use the global preference.
However there has been some confusion around which procedure you should use when and what the hierarchy is among these procedures. In this post we hope to clear up the confusion. Lets start by looking at the list of parameters you can change using the DBMS_STAT.SET_*_PREFS procedures.
- AUTOSTATS_TARGET (SET_GLOBAL_PREFS only)
- CASCADE
- DEGREE
- ESTIMATE_PERCENT
- METHOD_OPT
- NO_INVALIDATE
- GRANULARITY
- PUBLISH
- INCREMENTAL
- STALE_PERCENT
As mentioned above there are four DBMS_STATS.SET_*_PREFS procedures.
- SET_TABLE_PREFS
- SET_SCHEMA_PREFS
- SET_DATABASE_PREFS
- SET_GLOBAL_PREFS
The DBMS_STATS.SET_TABLE_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for the specified table only.
The DBMS_STATS.SET_SCHEMA_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for all of the existing objects in the specified schema. This procedure actually calls DBMS_STATS.SET_TABLE_PREFS for each of the tables in the specified schema. Since it uses DBMS_STATS.SET_TABLE_PREFS calling this procedure will not affect any new objects created after it has been run. New objects will pick up the GLOBAL_PREF values for all parameters.
The DBMS_STATS.SET_DATABASE_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for all of the user defined schemas in the database. This procedure actually calls DBMS_STATS.SET_TABLE_PREFS for each of the tables in each of the user defined schemas. Since it uses DBMS_STATS.SET_TABLE_PREFS this procedure will not affect any new objects created after it has been run. New objects will pick up the GLOBAL_PREF values for all parameters. It is also possible to include the Oracle owned schemas (sys, system, etc) by setting the ADD_SYS parameter to TRUE.
The DBMS_STATS.SET_GLOBAL_PREFS procedure allows you to change the default values of the parameters used by the DBMS_STATS.GATHER_*_STATS procedures for any object in the database that does not have an existing table preference. All parameters default to the global setting unless there is a table preference set or the parameter is explicitly set in the DBMS_STATS.GATHER_*_STATS command. Changes made by this procedure will affect any new objects created after it has been run as new objects will pick up the GLOBAL_PREF values for all parameters.
With GLOBAL_PREFS it is also possible to set a default value for one additional parameter, called AUTOSTAT_TARGET. This additional parameter controls what objects the automatic statistic gathering job (that runs in the nightly maintenance window) will look after. The possible values for this parameter are ALL,ORACLE, and AUTO. ALL means the automatic statistics gathering job will gather statistics on all objects in the database. ORACLE means that the automatic statistics gathering job will only gather statistics for Oracle owned schemas (sys, sytem, etc) Finally AUTO (the default) means Oracle will decide what objects to gather statistics on. Currently AUTO and ALL behave the same.
In summary, DBMS_STATS obeys the following hierarchy for parameter values, parameters values set in the DBMS_STAT.GATHER*_STATS command over rules everything. If the parameter has not been set in the command we check for a table level preference. If there is no table preference set we use the global preference.
Thursday, July 23, 2009
Will the Optimizer Team be at Oracle Open World 2009?
With only two and a half months to go until Oracle Open World in San Francisco, October 11-15th, we have gotten several requests asking if we plan to present any session at the conference.
We have two session and a demo station in the Database campground at this year's show. We will give a technical presentation on What to Expect from the Oracle Optimizer When Upgrading to Oracle Database 11g and the Oracle Optimizer Roundtable.
The technical session, which is on Tuesday Oct 13 at 2:30 pm, gives step by step instructions and detailed examples of how to use the new 11g features to ensure your upgrade goes smoothly and without any SQL plan regressions.
The roundtable, which is on Thursday Oct. 15th at 10:30 am, will give you a first hand opportunity to pose you burning Optimizer and statistics questions directly to a panel of our leading Optimizer developers. In fact if you plan to attend the roundtable and already know what questions you would like to ask, then please send them to us via email and we will be sure to include them. Other wise, you can hand in your questions at our demo station at any stage during the week, or as you enter the actual session. Just be sure to write your questions in clear block capitals!
We look forward to seeing you all at Oracle Open World.
Maria Colgan
We have two session and a demo station in the Database campground at this year's show. We will give a technical presentation on What to Expect from the Oracle Optimizer When Upgrading to Oracle Database 11g and the Oracle Optimizer Roundtable.
The technical session, which is on Tuesday Oct 13 at 2:30 pm, gives step by step instructions and detailed examples of how to use the new 11g features to ensure your upgrade goes smoothly and without any SQL plan regressions.
The roundtable, which is on Thursday Oct. 15th at 10:30 am, will give you a first hand opportunity to pose you burning Optimizer and statistics questions directly to a panel of our leading Optimizer developers. In fact if you plan to attend the roundtable and already know what questions you would like to ask, then please send them to us via email and we will be sure to include them. Other wise, you can hand in your questions at our demo station at any stage during the week, or as you enter the actual session. Just be sure to write your questions in clear block capitals!
We look forward to seeing you all at Oracle Open World.
Maria Colgan
Tuesday, May 26, 2009
Why do I have hundreds of child cursors when cursor_sharing set to similar in 10g
Recently we received several questions regarding a usual situation where a SQL Statement has hundreds of child cursors. This is in fact the expected behavior when
- CURSOR_SHARING is set to similar
- Bind peeking is in use
- And a histogram is present on the column used in the where clause predicate of query
You must now be wondering why this is the expected behavior. In order to explain, let's step back and begin by explaining what CURSOR_SHARING actually does. CURSOR_SHARING was introduced to help relieve pressure put on the shared pool, specifically the cursor cache, from applications that use literal values rather than bind variables in their SQL statements. It achieves this by replacing the literal values with system generated bind variables thus reducing the number of (parent) cursors in the cursor cache. However, there is also a caveat or additional requirement on CURSOR_SHARING, which is that the use of system generated bind should not negatively affect the performance of the application. CURSOR_SHARING has three possible values: EXACT, SIMILAR, and FORCE. The table below explains the impact of each setting with regards to the space used in the cursor cache and the query performance.
| CURSOR_SHARING VALUE | SPACE USED IN SHARED POOL | QUERY PERFORMANCE |
|---|---|---|
| EXACT (No literal replacement) | Worst possible case - each stmt issued has its own parent cursor | Best possible case as each stmt has its own plan generated for it based on the value of the literal value present in the stmt |
| FORCE | Best possible case as only one parent and child cursor for each distinct stmt | Potentially the worst case as only one plan will be used for each distinct stmt and all occurrences of that stmt will use that plan |
| SIMILAR without histogram present | Best possible case as only one parent and child cursor for each distinct stmt | Potentially the worst case as only one plan will be used for each distinct stmt and all occurrences of that stmt will use that plan |
| SIMILAR with histogram present | Not quite as much space used as with EXACT but close. Instead of each stmt having its own parent cursor they will have their own child cursor (which uses less space) | Best possible case as each stmt has its own plan generated for it based on the value of the literal value present in the stmt |
In this case the statement with hundreds of children falls into the last category in the above table, having CURSOR_SHARING set to SIMILAR and a histogram on the columns used in the where clause predicate of the statement. The presence of the histogram tells the optimizer that there is a data skew in that column. The data skew means that there could potentially be multiple execution plans for this statement depending on the literal value used. In order to ensure we don't impact the performance of the application, we will peek at the bind variable values and create a new child cursor for each distinct value. Thus ensuring each bind variable value will get the most optimal execution plan. It's probably easier to understand this issue by looking at an example. Let's assume there is an employees table with a histogram on the job column and CURSOR_SHARING has been set to similar. The following query is issued
select * from employees where job = 'Clerk';
The literal value 'Clerk' will be replaced by a system generated bind variable B1 and a parent cursor will be created as
select * from employees where job = :B1;
The optimizer will peek the bind variable B1 and use the literal value 'Clerk' to determine the execution plan. 'Clerk' is a popular value in the job column and so a full table scan plan is selected and child cursor C1 is created for this plan. The next time the query is executed the where clause predicate is job='VP' so B1 will be set to 'VP', this is not a very popular value in the job column so an index range scan is selected and child cursor C2 is created. The third time the query is executed the where clause predicate is job ='Engineer' so the value for B1 is set to 'Engineer'. Again this is a popular value in the job column and so a full table scan plan is selected and a new child cursor C3 is created. And so on until we have seen all of the distinct values for job column. If B1 is set to a previously seen value, say 'Clerk', then we would reuse child cursor C1.
| Value for B1 | Plan Used | Cursor Number |
|---|---|---|
| Clerk | Full Table Scan | C1 |
| VP | Index Range Scan | C2 |
| Engineer | Full Table Scan | C3 |
As each of these cursors is actually a child cursor and not a new parent cursor you will still be better off than with CURSOR_SHARING set to EXACT as a child cursor takes up less space in the cursor cache. A child cursor doesn't contain all of the information stored in a parent cursor, for example, the SQL text is only stored in the parent cursor and not in each child.
Now that you know the explanation for all of the child cursors you are seeing you need to decide if it is a problem for you and if so which aspect affects you most, space used in the SHARED_POOL or query performance. If your goal is to guarantee the application performance is not affected by setting CURSOR_SHARING to SIMILAR then keep the system settings unchanged. If your goal is to reduce the space used in the shared pool then you can use one of the following solutions with different scopes:
- Individual SQL statements - drop the histograms on the columns for each of the affected SQL statements
- System-wide - set CURSOR_SHARING to FORCE this will ensure only one child cursor per SQL statement
Both of these solutions require testing to ensure you get the desired effect on your system. Oracle Database 11g provides a much better solution using the Adaptive Cursor Sharing feature. In Oracle Database 11g, all you need to do is set CURSOR_SHARING to FORCE and keep the histograms. With Adaptive Cursor Sharing, the optimizer will create a cursor only when its plan is different from any of the plans used by other child cursors. So in the above example, you will get two child cursors (C1 and C2) instead of 3.
Sunday, April 12, 2009
Wednesday, February 11, 2009
Maintaining statistics on large partitioned tables
We have gotten a lot of questions recently regarding how to gather and maintain optimizer statistics on large partitioned tables. The majority of these questions can be summarized into two topics:
Expensive global statistics collection
Assume we have table called SALES that is range partitioned by day on the SALES_DATE column. At the end of every day data is loaded into latest partition and partition statistics are gathered. Global statistics are only gathered at the end of every month because gathering them is very time and resource intensive. Use the following steps in order to maintain global statistics after every load.
Note: that the incremental maintenance feature was introduced in Oracle Database 11g Release 1. However, we also provide a solution in Oracle Database10g Release 2 (10.2.0.4) that simulates the same behavior. The 10g solution is a new value, 'APPROX_GLOBAL AND PARTITION' for the GRANULARITY parameter of the GATHER_TABLE_STATS procedures. It behaves the same as the incremental maintenance feature except that we don’t update the NDV for non-partitioning columns and number of distinct keys of the index at the global level. For partitioned column we update the NDV as the sum of NDV at the partition levels. Also we set the NDV of columns of unique indexes as the number of rows of the table. In general, non-partitioning column NDV at the global level becomes stale less often. It may be possible to collect global statistics less frequently then the default (when table changes 10%) since approx_global option maintains most of the global statistics accurately.
Let's take a look at an example to see how you would effectively use the Oracle Database 10g approach.
After the data load is complete, gather statistics using DBMS_STATS.GATHER_TABLE_STATS for the last partition (say SALES_11FEB2009), specify granularity => 'APPROX_GLOBAL AND PARTITION'. It will collect statistics for the specified partition and derive global statistics from partition statistics (except for NDV as described before).
EXEC DBMS_STATS.GATHER_TABLE_STATS ('SH', 'SALES', 'SALES_11FEB2009', GRANULARITY => 'APPROX_GLOBAL AND PARTITION');
It is necessary to install the one off patch for bug 8719831 if you are using copy_table_stats procedure or APPROX_GLOBAL option in 10.2.0.4 (patch 8877245) or in 11.1.0.7 (patch 8877251).
Maria Colgan
- When queries access a single partition with stale or non-existent partition level statistics I get a sub optimal plan due to “Out of Range” values
- Global statistics collection is extremely expensive in terms of time and system resources
This article will describe both of these issues and explain how you can address them both in Oracle Database 10gR2 and 11gR1.
Out of Range
Large tables are often decomposed into smaller pieces called partitions in order to improve query performance and ease of data management. The Oracle query optimizer relies on both the statistics of the entire table (global statistics) and the statistics of the individual partitions (partition statistics) to select a good execution plan for a SQL statement. If the query needs to access only a single partition, the optimizer uses only the statistics of the accessed partition. If the query access more than one partition, it uses a combination of global and partition statistics.
“Out of Range” means that the value supplied in a where clause predicate is outside the domain of values represented by the [minimum, maximum] column statistics. The optimizer prorates the selectivity based on the distance between the predicate value and the maximum value (assuming the value is higher than the max), that is, the farther the value is from the maximum value, the lower the selectivity will be. This situation occurs most frequently in tables that are range partitioned by a date column, a new partition is added, and then queried while rows are still being loaded in the new partition. The partition statistics will be stale very quickly due to the continuous trickle feed load even if the statistics get refreshed periodically. The maximum value known to the optimizer is not correct leading to the “Out of Range” condition. The under-estimation of selectivity often leads the query optimizer to pick a sub optimal plan. For example, the query optimizer would pick an index access path while a full scan is a better choice.
The "Out of Range" condition can be prevented by using the new copy table statistics procedure available in Oracle Database10.2.0.4 and 11g. This procedure copies the statistics of the source [sub] partition to the destination [sub] partition. It also copies the statistics of the dependent objects: columns, local (partitioned) indexes etc. It adjusts the minimum and maximum values of the partitioning column as follows; it uses the high bound partitioning value as the maximum value of the first partitioning column (it is possible to have concatenated partition columns) and high bound partitioning value of the previous partition as the minimum value of the first partitioning column for range partitioned table. It can optionally scale some of the other statistics like the number of blocks, number of rows etc. of the destination partition.
Assume we have a table called SALES that is ranged partitioned by quarter on the SALES_DATE column. At the end of every day data is loaded into latest partition. However, statistics are only gathered at the end of every quarter when the partition is fully loaded. Assuming global and partition level statistics (for all fully loaded partitions) are up to date, use the following steps in order to prevent getting a sub-optimal plan due to “out of range”.
- Lock the table statistics using LOCK_TABLE_STATS procedure in DBMS_STATS. This is to avoid interference from auto statistics job.
EXEC DBMS_STATS.LOCK_TABLE_STATS('SH','SALES'); - Before beginning the initial load into each new partition (say SALES_Q4_2000) copy the statistics from the previous partition (say SALES_Q3_2000) using COPY_TABLE_STATS. You need to specify FORCE=>TRUE to override the statistics lock.
EXEC DBMS_STATS.COPY_TABLE_STATS ('SH', 'SALES', 'SALES_Q3_2000', 'SALES_Q4_2000', FORCE=>TRUE);
Expensive global statistics collection
In data warehouse environment it is very common to do a bulk load directly into one or more empty partitions. This will make the partition statistics stale and may also make the global statistics stale. Re-gathering statistics for the effected partitions and for the entire table can be very time consuming. Traditionally, statistics collection is done in a two-pass approach:
The full scan of the table for global statistics collection can be very expensive depending on the size of the table. Note that the scan of the entire table is done even if we change a small subset of partitions.
In Oracle Database 11g, we avoid scanning the whole table when computing global statistics by deriving the global statistics from the partition statistics. Some of the statistics can be derived easily and accurately from partition statistics. For example, number of rows at global level is the sum of number of rows of partitions. Even global histogram can be derived from partition histograms. But the number of distinct values (NDV) of a column cannot be derived from partition level NDVs. So, Oracle maintains another structure called a synopsis for each column at the partition level. A synopsis can be considered as sample of distinct values. The NDV can be accurately derived from synopses. We can also merge multiple synopses into one. The global NDV is derived from the synopsis generated by merging all of the partition level synopses. To summarize
Incremental maintenance feature is disabled by default. It can be enabled by changing the INCREMENTAL table preference to true. It can also be enabled for a particular schema or at the database level. If you are interested in more details of the incremental maintenance feature, please refer to the following paper presented in SIGMOD 2008 and to our previous blog entry on new ndv gathering in 11g.
Assume we have table called SALES that is range partitioned by day on the SALES_DATE column. At the end of every day data is loaded into latest partition and partition statistics are gathered. Global statistics are only gathered at the end of every month because gathering them is very time and resource intensive. Use the following steps in order to maintain global statistics after every load.
- Turn on incremental feature for the table.
EXEC DBMS_STATS.SET_TABLE_PREFS('SH','SALES','INCREMENTAL','TRUE'); - At the end of every load gather table statistics using GATHER_TABLE_STATS command. You don’t need to specify the partition name. Also, do not specify the granularity parameter. The command will collect statistics for partitions with stale or missing statistics and update the global statistics based on the partition level statistics and synopsis.
EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','SALES');
Note: that the incremental maintenance feature was introduced in Oracle Database 11g Release 1. However, we also provide a solution in Oracle Database10g Release 2 (10.2.0.4) that simulates the same behavior. The 10g solution is a new value, 'APPROX_GLOBAL AND PARTITION' for the GRANULARITY parameter of the GATHER_TABLE_STATS procedures. It behaves the same as the incremental maintenance feature except that we don’t update the NDV for non-partitioning columns and number of distinct keys of the index at the global level. For partitioned column we update the NDV as the sum of NDV at the partition levels. Also we set the NDV of columns of unique indexes as the number of rows of the table. In general, non-partitioning column NDV at the global level becomes stale less often. It may be possible to collect global statistics less frequently then the default (when table changes 10%) since approx_global option maintains most of the global statistics accurately.
Let's take a look at an example to see how you would effectively use the Oracle Database 10g approach.
After the data load is complete, gather statistics using DBMS_STATS.GATHER_TABLE_STATS for the last partition (say SALES_11FEB2009), specify granularity => 'APPROX_GLOBAL AND PARTITION'. It will collect statistics for the specified partition and derive global statistics from partition statistics (except for NDV as described before).
EXEC DBMS_STATS.GATHER_TABLE_STATS ('SH', 'SALES', 'SALES_11FEB2009', GRANULARITY => 'APPROX_GLOBAL AND PARTITION');
It is necessary to install the one off patch for bug 8719831 if you are using copy_table_stats procedure or APPROX_GLOBAL option in 10.2.0.4 (patch 8877245) or in 11.1.0.7 (patch 8877251).
Maria Colgan
Monday, February 2, 2009
SQL Plan Management (Part 4 of 4): User Interfaces and Other Features
In the first three parts of this article, we have seen how SQL plan baselines are created, used and evolved. In this final installment, we will show some user interfaces, describe the interaction of SPM with other features and answer some of your questions.
DBMS_SPM package
A new package, DBMS_SPM, allows you to manage plan histories. We have already seen in previous examples how you can use it to create and evolve SQL plan baselines. Other management functions include changing attributes (like enabled status and plan name) of plans or dropping plans. You need the ADMINISTER SQL MANAGEMENT OBJECT privilege to execute this package.
Viewing the plan history
Regardless of how a plan history is created, you can view details about the various plans in the view DBA_SQL_PLAN_BASELINES. At the end of Part 3 of this blog, we saw that the SQL statement had two accepted plans:
SQL> select sql_text, sql_handle, plan_name, enabled, accepted
2 from dba_sql_plan_baselines;
SQL_TEXT SQL_HANDLE PLAN_NAME ENA ACC
------------------------ ------------------------ ----------------------------- --- ---
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
SQL_TEXT SQL_HANDLE PLAN_NAME ENA ACC
------------------------ ------------------------ ----------------------------- --- ---
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0888547d3 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SQL handle: SYS_SQL_4bf04d85fcc170b0
SQL text: select p.prod_name, s.amount_sold, t.calendar_year from sales s,
products p, times t where s.prod_id = p.prod_id and s.time_id =
t.time_id and p.prod_id < :pid
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b0888547d3
Enabled: YES Fixed: NO Accepted: YES Origin: MANUAL-LOAD
--------------------------------------------------------------------------------
Plan hash value: 2290436051
---------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL | TIMES |
| 4 | PARTITION RANGE ALL | |
| 5 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 6 | BITMAP CONVERSION TO ROWIDS | |
| 7 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 8 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 9 | INDEX RANGE SCAN | PRODUCTS_PK |
---------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b08cbcb825
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
--------------------------------------------------------------------------------
Plan hash value: 2361178149
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
| 5 | TABLE ACCESS FULL | TIMES |
| 6 | TABLE ACCESS FULL | PRODUCTS |
------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b0a62d0f4d
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
--------------------------------------------------------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
72 rows selected.
Parameters
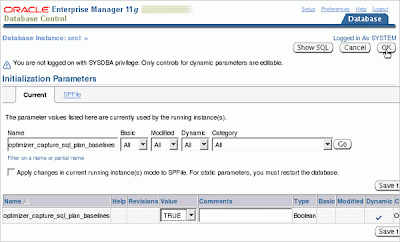
Two parameters allow you to control SPM. The first, optimizer_capture_sql_plan_baselines, which is FALSE by default, allows you to automatically capture plans. SPM will start managing every repeatable SQL statement that is executed and will create a plan history for it. The first plan that is captured will beautomatically accepted. Subsequent plans for these statements will not be accepted until they are evolved.
The second parameter, optimizer_use_sql_plan_baselines, is TRUE by default. It allows the SPM aware optimizer to use the SQL plan baseline if available when compiling a SQL statement. If you set this parameter to FALSE, the SPM aware optimizer will be disabled and you will get the regular cost-based optimizer which will select the best plan based on estimated cost.
SPM and SQL profiles
A SQL statement can have both a SQL profile and a SQL plan baseline. Such a case was described in Part 3 where we evolved a SQL plan baseline by accepting a SQL profile. In this case, the SPM aware optimizer will use both the SQL profile and the SQL plan baseline. The SQL profile contains additional information that helps the optimizer to accurately cost each accepted plan and select the best one. The SPM aware optimizer may choose a different accepted plan when a SQL profile is present than when it is not.
SPM and stored outlines
It is possible for a SQL statement to have a stored outline as well as a SQL plan baseline. If a stored outline exists for a SQL statement and is enabled for use, then the optimizer will use it, ignoring the SQL plan baseline. In other words, the stored outline trumps a SQL plan baseline. If you are using stored outlines, you can test SPM by creating SQL plan baselines and disabling the stored outlines. If you are satisfied with SPM, you can either drop the stored outlines or leave them disabled. If SPM doesn't work for you (and we would love to know why), you can re-enable the stored outlines.
If you are using stored outlines, be aware of their limitations:
One question that readers have is what we plan to do with the stored outlines feature. Here is the official word in Chapter 20 of Oracle's Performance Tuning Guide:
SPM and adaptive cursor sharing
Adaptive cursor sharing (ACS) may generate multiple cursors for a given bind sensitive SQL statement if it is determined that a single plan is not optimal under all conditions. Each cursor is generated by forcing a hard parse of the statement. The optimizer will normally select the plan with the best cost upon each hard parse.
When you have a SQL plan baseline for a statement, the SPM aware optimizer will select the best accepted plan as the optimal plan. This also applies for the hard parse of a bind sensitive statement. There may be multiple accepted plans, each of which is optimal for different bind sets. With SPM and ACS enabled, the SPM aware optimizer will select the best plan for the current bind set.
Thus, if a hard parse occurs, the normal SPM plan selection algorithm is used regardless of whether a statement is bind sensitive.
Enterprise Manager
You can view SQL plan baselines and configure and manage most SPM tasks through the Enterprise Manager. The screenshots below show two of these tasks.

Further Reading
More details about SPM are available in the Oracle documentation, especially Chapter 15 of the Performance Tuning Guide. There is also a whitepaper, and a paper published in the VLDB 2008 conference. The VLDB paper also has experimental results that show how SPM prevents performance regressions while simultaneously allowing better plans to be used.
DBMS_SPM package
A new package, DBMS_SPM, allows you to manage plan histories. We have already seen in previous examples how you can use it to create and evolve SQL plan baselines. Other management functions include changing attributes (like enabled status and plan name) of plans or dropping plans. You need the ADMINISTER SQL MANAGEMENT OBJECT privilege to execute this package.
Viewing the plan history
Regardless of how a plan history is created, you can view details about the various plans in the view DBA_SQL_PLAN_BASELINES. At the end of Part 3 of this blog, we saw that the SQL statement had two accepted plans:
SQL> select sql_text, sql_handle, plan_name, enabled, accepted
2 from dba_sql_plan_baselines;
SQL_TEXT SQL_HANDLE PLAN_NAME ENA ACC
------------------------ ------------------------ ----------------------------- --- ---
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
The SQL handle is a unique identifier for each SQL statement that you can use when managing your plan history using the DBMS_SPM package.
Creating an accepted plan by modifying the SQL text
Some of you may be manually tuning SQL statements by adding hints or otherwise modifying the SQL text. If you enable automatic capture of SQL plans and then execute this statement, you will be creating a SQL plan baseline for this modified statement. What you most likely want, however, is to add this plan to the plan history of the original SQL statement. Here's how you can do this using the above SQL statement as an example.
Let's modify the SQL statement, execute it and look at the plan:
SQL> var pid number
SQL> exec :pid := 100;
PL/SQL procedure successfully completed.
SQL> select /*+ leading(t) */ p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
9 rows selected.
SQL> select * from table(dbms_xplan.display_cursor('b17wnz4y8bqv1', 0, 'basic note'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
EXPLAINED SQL STATEMENT:
------------------------
select /*+ leading(t) */ p.prod_name, s.amount_sold, t.calendar_year
from sales s, products p, times t where s.prod_id = p.prod_id and
s.time_id = t.time_id and p.prod_id < :pid
Plan hash value: 2290436051
---------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL | TIMES |
| 4 | PARTITION RANGE ALL | |
| 5 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 6 | BITMAP CONVERSION TO ROWIDS | |
| 7 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 8 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 9 | INDEX RANGE SCAN | PRODUCTS_PK |
---------------------------------------------------------------
23 rows selected.
We can now create a new accepted plan for the original SQL statement by associating the modified statement's plan to the original statement's sql handle (obtained from DBA_SQL_PLAN_BASELINES):
SQL> var pls number
SQL> exec :pls := dbms_spm.load_plans_from_cursor_cache( -
> sql_id => 'b17wnz4y8bqv1', -
> plan_hash_value => 2290436051, -
> sql_handle => 'SYS_SQL_4bf04d85fcc170b0');
If the original SQL statement does not already have a plan history (and thus no SQL handle), another version of load_plans_from_cursor_cache allows you to specify the original statement's text.
To confirm that we now have three accepted plans for our SQL statement, let's check in DBA_SQL_PLAN_BASELINES:
SQL> select sql_text, sql_handle, plan_name, enabled, accepted
2 from dba_sql_plan_baselines;
SQL_TEXT SQL_HANDLE PLAN_NAME ENA ACC
------------------------ ------------------------ ----------------------------- --- ---
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0888547d3 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
select p.prod_name, s.am SYS_SQL_4bf04d85fcc170b0 SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
ount_sold, t.calendar_ye
ar
from sales s, products p
, times t
where s.prod_id = p.prod
_id
and s.time_id = t.time
_id
and p.prod_id < :pid
Displaying plans
When the optimizer uses an accepted plan for a SQL statement, you can see it in the plan table (for explain) or V$SQL_PLAN (for shared cursors). Let's explain the SQL statement above and display its plan:
SQL> explain plan for
2 select p.prod_name, s.amount_sold, t.calendar_year
3 from sales s, products p, times t
4 where s.prod_id = p.prod_id
5 and s.time_id = t.time_id
6 and p.prod_id < :pid;
Explained.
SQL> select * from table(dbms_xplan.display('plan_table', null, 'basic note'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
Note
-----
- SQL plan baseline "SYS_SQL_PLAN_fcc170b0a62d0f4d" used for this statement
22 rows selected.
The note at the bottom tells you that the optimizer used an accepted plan.
A plan history might have multiple plans. You can see one of the accepted plans if the optimizer selects it for execution. But what if you want to display some or all of the other plans? You can do this using the display_sql_plan_baseline function in the DBMS_XPLAN package. Using the above example, here's how you can display the plan for all plans in the plan history.
SQL> select *
2 from table(dbms_xplan.display_sql_plan_baseline(
3 sql_handle => 'SYS_SQL_4bf04d85fcc170b0', format => 'basic'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SQL handle: SYS_SQL_4bf04d85fcc170b0
SQL text: select p.prod_name, s.amount_sold, t.calendar_year from sales s,
products p, times t where s.prod_id = p.prod_id and s.time_id =
t.time_id and p.prod_id < :pid
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b0888547d3
Enabled: YES Fixed: NO Accepted: YES Origin: MANUAL-LOAD
--------------------------------------------------------------------------------
Plan hash value: 2290436051
---------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL | TIMES |
| 4 | PARTITION RANGE ALL | |
| 5 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 6 | BITMAP CONVERSION TO ROWIDS | |
| 7 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 8 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 9 | INDEX RANGE SCAN | PRODUCTS_PK |
---------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b08cbcb825
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
--------------------------------------------------------------------------------
Plan hash value: 2361178149
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
| 5 | TABLE ACCESS FULL | TIMES |
| 6 | TABLE ACCESS FULL | PRODUCTS |
------------------------------------------
--------------------------------------------------------------------------------
Plan name: SYS_SQL_PLAN_fcc170b0a62d0f4d
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
--------------------------------------------------------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
72 rows selected.
Parameters
Two parameters allow you to control SPM. The first, optimizer_capture_sql_plan_baselines, which is FALSE by default, allows you to automatically capture plans. SPM will start managing every repeatable SQL statement that is executed and will create a plan history for it. The first plan that is captured will beautomatically accepted. Subsequent plans for these statements will not be accepted until they are evolved.
The second parameter, optimizer_use_sql_plan_baselines, is TRUE by default. It allows the SPM aware optimizer to use the SQL plan baseline if available when compiling a SQL statement. If you set this parameter to FALSE, the SPM aware optimizer will be disabled and you will get the regular cost-based optimizer which will select the best plan based on estimated cost.
SPM and SQL profiles
A SQL statement can have both a SQL profile and a SQL plan baseline. Such a case was described in Part 3 where we evolved a SQL plan baseline by accepting a SQL profile. In this case, the SPM aware optimizer will use both the SQL profile and the SQL plan baseline. The SQL profile contains additional information that helps the optimizer to accurately cost each accepted plan and select the best one. The SPM aware optimizer may choose a different accepted plan when a SQL profile is present than when it is not.
SPM and stored outlines
It is possible for a SQL statement to have a stored outline as well as a SQL plan baseline. If a stored outline exists for a SQL statement and is enabled for use, then the optimizer will use it, ignoring the SQL plan baseline. In other words, the stored outline trumps a SQL plan baseline. If you are using stored outlines, you can test SPM by creating SQL plan baselines and disabling the stored outlines. If you are satisfied with SPM, you can either drop the stored outlines or leave them disabled. If SPM doesn't work for you (and we would love to know why), you can re-enable the stored outlines.
If you are using stored outlines, be aware of their limitations:
- You can only have one stored outline at a time for a given SQL statement. This may be fine in some cases, but a single plan is not necessarily the best when the statement is executed under varying conditions (e.g., bind values).
- The second limitation is related to the first. Stored outlines do not allow for evolution. That is, even if a better plan exists, the stored outline will continue to be used, potentially degrading your system's performance. To get the better plan, you have to manually drop the current stored outline and generate a new one.
- If an access path (e.g., an index) used in a stored outline is dropped or otherwise becomes unusable, the partial stored outline will continue to be used with the potential of a much worse plan.
One question that readers have is what we plan to do with the stored outlines feature. Here is the official word in Chapter 20 of Oracle's Performance Tuning Guide:
Stored outlines will be desupported in a future release in favor of SQL plan management. In Oracle Database 11g Release 1 (11.1), stored outlines continue to function as in past releases. However, Oracle strongly recommends that you use SQL plan management for new applications. SQL plan management creates SQL plan baselines, which offer superior SQL performance and stability compared with stored outlines.
If you have existing stored outlines, consider migrating them to SQL plan baselines by using the LOAD_PLANS_FROM_CURSOR_CACHE or LOAD_PLANS_FROM_SQLSET procedure of the DBMS_SPM package. When the migration is complete, you should disable or remove the stored outlines.
SPM and adaptive cursor sharing
Adaptive cursor sharing (ACS) may generate multiple cursors for a given bind sensitive SQL statement if it is determined that a single plan is not optimal under all conditions. Each cursor is generated by forcing a hard parse of the statement. The optimizer will normally select the plan with the best cost upon each hard parse.
When you have a SQL plan baseline for a statement, the SPM aware optimizer will select the best accepted plan as the optimal plan. This also applies for the hard parse of a bind sensitive statement. There may be multiple accepted plans, each of which is optimal for different bind sets. With SPM and ACS enabled, the SPM aware optimizer will select the best plan for the current bind set.
Thus, if a hard parse occurs, the normal SPM plan selection algorithm is used regardless of whether a statement is bind sensitive.
Enterprise Manager
You can view SQL plan baselines and configure and manage most SPM tasks through the Enterprise Manager. The screenshots below show two of these tasks.
Setting init.ora parameters for SPM

Loading SQL plan baselines from cursor cache

Further Reading
More details about SPM are available in the Oracle documentation, especially Chapter 15 of the Performance Tuning Guide. There is also a whitepaper, and a paper published in the VLDB 2008 conference. The VLDB paper also has experimental results that show how SPM prevents performance regressions while simultaneously allowing better plans to be used.
Monday, January 26, 2009
SQL Plan Management (Part 3 of 4): Evolving SQL Plan Baselines
In the example in Part 2, we saw that the optimizer used an accepted plan instead of a brand new plan. The statement has two plans in its plan history, but only one is accepted and thus in the SQL plan baseline:
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL> exec :report := dbms_spm.evolve_sql_plan_baseline();
PL/SQL procedure successfully completed.
SQL> print :report
REPORT
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
Evolve SQL Plan Baseline Report
-------------------------------------------------------------------------------
Inputs:
-------
SQL_HANDLE =
PLAN_NAME =
TIME_LIMIT = DBMS_SPM.AUTO_LIMIT
VERIFY = YES
COMMIT = YES
Plan: SYS_SQL_PLAN_fcc170b08cbcb825
-----------------------------------
Plan was verified: Time used .1 seconds.
Passed performance criterion: Compound improvement ratio >= 10.13
Plan was changed to an accepted plan.
Baseline Plan Test Plan Improv. Ratio
------------- --------- -------------
Execution Status: COMPLETE COMPLETE
Rows Processed: 960 960
Elapsed Time(ms): 19 15 1.27
CPU Time(ms): 18 15 1.2
Buffer Gets: 1188 116 10.24
Disk Reads: 0 0
Direct Writes: 0 0
Fetches: 0 0
Executions: 1 1
-------------------------------------------------------------------------------
Report Summary
-------------------------------------------------------------------------------
Number of SQL plan baselines verified: 1.
Number of SQL plan baselines evolved: 1.
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL> exec :tname := dbms_sqltune.create_tuning_task(sql_id => 'bfbr3zrg9d5cc');
PL/SQL procedure successfully completed.
SQL> exec dbms_sqltune.execute_tuning_task(task_name => :tname);
PL/SQL procedure successfully completed.
SQL> select dbms_sqltune.report_tuning_task(:tname, 'TEXT', 'BASIC') FROM dual;
DBMS_SQLTUNE.REPORT_TUNING_TASK(:TNAME,'TEXT','BASIC')
-------------------------------------------------------------------------------
GENERAL INFORMATION SECTION
-------------------------------------------------------------------------------
Tuning Task Name : TASK_505
Tuning Task Owner : SH
Workload Type : Single SQL Statement
Scope : COMPREHENSIVE
Time Limit(seconds): 1800
Completion Status : COMPLETED
Started at : 11/11/2008 16:43:12
Completed at : 11/11/2008 16:43:13
-------------------------------------------------------------------------------
Schema Name: SH
SQL ID : bfbr3zrg9d5cc
SQL Text : select p.prod_name, s.amount_sold, t.calendar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
-------------------------------------------------------------------------------
FINDINGS SECTION (1 finding)
-------------------------------------------------------------------------------
1- A potentially better execution plan was found for this statement.
-------------------------------------------------------------------------------
EXPLAIN PLANS SECTION
-------------------------------------------------------------------------------
1- Original With Adjusted Cost
------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
2- Original With Adjusted Cost
------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
3- Using SQL Profile
--------------------
Plan hash value: 2361178149
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
| 5 | TABLE ACCESS FULL | TIMES |
| 6 | TABLE ACCESS FULL | PRODUCTS |
------------------------------------------
-------------------------------------------------------------------------------
SQL> exec dbms_sqltune.accept_sql_profile(task_name => :tname);
PL/SQL procedure successfully completed.
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL> select sql_text, type, status from dba_sql_profiles;
SQL_TEXT TYPE STATUS
---------------------------------------- ------- --------
select p.prod_name, s.amount_sold, t.cal MANUAL ENABLED
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
Non-accepted plans can be verified by executing the evolve_sql_plan_baseline function. This function will execute the non-accepted plan and compare its performance to the best accepted plan. The execution is performed using the conditions (e.g., bind values, parameters, etc.) in effect at the time the non-accepted plan was added to the plan history. If the non-accepted plan's performance is better, the function will make it accepted, thus adding it to the SQL plan baseline. Let's see what happens when we execute this function:
SQL> var report clob;
SQL> exec :report := dbms_spm.evolve_sql_plan_baseline();
PL/SQL procedure successfully completed.
SQL> print :report
REPORT
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
Evolve SQL Plan Baseline Report
-------------------------------------------------------------------------------
Inputs:
-------
SQL_HANDLE =
PLAN_NAME =
TIME_LIMIT = DBMS_SPM.AUTO_LIMIT
VERIFY = YES
COMMIT = YES
Plan: SYS_SQL_PLAN_fcc170b08cbcb825
-----------------------------------
Plan was verified: Time used .1 seconds.
Passed performance criterion: Compound improvement ratio >= 10.13
Plan was changed to an accepted plan.
Baseline Plan Test Plan Improv. Ratio
------------- --------- -------------
Execution Status: COMPLETE COMPLETE
Rows Processed: 960 960
Elapsed Time(ms): 19 15 1.27
CPU Time(ms): 18 15 1.2
Buffer Gets: 1188 116 10.24
Disk Reads: 0 0
Direct Writes: 0 0
Fetches: 0 0
Executions: 1 1
-------------------------------------------------------------------------------
Report Summary
-------------------------------------------------------------------------------
Number of SQL plan baselines verified: 1.
Number of SQL plan baselines evolved: 1.
The plan verification report shows that the new plan's performance was better and so it was made accepted and became part of the SQL plan baseline. We can confirm it by looking in the dba_sql_plan_baselines view:
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
The SQL plan baseline now has two accepted plans: SYS_SQL_PLAN_fcc170b08cbcb825 is now accepted.
You can either execute the evolve_sql_plan_baseline() function manually or schedule it to run automatically in a maintenance window.
Another way of evolving a SQL plan baseline is to use the SQL Tuning Advisor. Instead of executing evolve_sql_plan_baseline, suppose we start from the original state where we have one accepted and one non-accepted plan:
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
You can execute the SQL Tuning Advisor on the cursor in the cursor cache:
SQL> var tname varchar2(30);
SQL> exec :tname := dbms_sqltune.create_tuning_task(sql_id => 'bfbr3zrg9d5cc');
PL/SQL procedure successfully completed.
SQL> exec dbms_sqltune.execute_tuning_task(task_name => :tname);
PL/SQL procedure successfully completed.
SQL> select dbms_sqltune.report_tuning_task(:tname, 'TEXT', 'BASIC') FROM dual;
DBMS_SQLTUNE.REPORT_TUNING_TASK(:TNAME,'TEXT','BASIC')
-------------------------------------------------------------------------------
GENERAL INFORMATION SECTION
-------------------------------------------------------------------------------
Tuning Task Name : TASK_505
Tuning Task Owner : SH
Workload Type : Single SQL Statement
Scope : COMPREHENSIVE
Time Limit(seconds): 1800
Completion Status : COMPLETED
Started at : 11/11/2008 16:43:12
Completed at : 11/11/2008 16:43:13
-------------------------------------------------------------------------------
Schema Name: SH
SQL ID : bfbr3zrg9d5cc
SQL Text : select p.prod_name, s.amount_sold, t.calendar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
-------------------------------------------------------------------------------
FINDINGS SECTION (1 finding)
-------------------------------------------------------------------------------
1- A potentially better execution plan was found for this statement.
-------------------------------------------------------------------------------
EXPLAIN PLANS SECTION
-------------------------------------------------------------------------------
1- Original With Adjusted Cost
------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
2- Original With Adjusted Cost
------------------------------
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
3- Using SQL Profile
--------------------
Plan hash value: 2361178149
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
| 5 | TABLE ACCESS FULL | TIMES |
| 6 | TABLE ACCESS FULL | PRODUCTS |
------------------------------------------
-------------------------------------------------------------------------------
SQL> exec dbms_sqltune.accept_sql_profile(task_name => :tname);
PL/SQL procedure successfully completed.
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
SQL> select sql_text, type, status from dba_sql_profiles;
SQL_TEXT TYPE STATUS
---------------------------------------- ------- --------
select p.prod_name, s.amount_sold, t.cal MANUAL ENABLED
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
What we see here is that SQL Tuning Advisor found a tuned plan (that coincidentally happened to be the non-accepted plan in our plan history). When we accepted the recommended SQL profile, the SQL Tuning Advisor created a SQL profile and also changed the non-accepted plan to accepted status, thus evolving the SQL plan baseline to two plans.
Note that the SQL Tuning Advisor may also find a completely new tuned plan, one that is not in the plan history. If you then accept the recommended SQL profile, the SQL Tuning Advisor will create a SQL profile and also add the tuned plan to the SQL plan baseline.
Thus, you can evolve a SQL plan baseline either by executing the evolve_sql_plan_baseline function or by using the SQL Tuning Advisor. New and provably better plans will be added by either of these methods to the SQL plan baseline.
Tuesday, January 20, 2009
SQL Plan Management (Part 2 of 4): SPM Aware Optimizer
(Keep sending your feedback and questions. We'll address them in Part 4.)
In Part 1, we saw how you can create SQL plan baselines. After you create a SQL plan baseline for a statement, subsequent executions of that statement will use the SQL plan baseline. From all the plans in the SQL plan baseline, the optimizer will select the one with the best cost in the current environment (including bind values, current statistics, parameters, etc.). The optimizer will also generate the best-cost plan that it would otherwise have used without a SQL plan baseline. However, this best-cost plan will not be used but instead added to the statement's plan history for later verification. In other words, the optimizer will use a known plan from the SQL plan baseline instead of a new and hitherto unknown plan. This guarantees no performance regression.
Let's see this plan selection process in action. First, we create a SQL plan baseline by enabling automatic plan capture and executing the query twice:
SQL> alter session set optimizer_capture_sql_plan_baselines = true;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
In Part 1, we saw how you can create SQL plan baselines. After you create a SQL plan baseline for a statement, subsequent executions of that statement will use the SQL plan baseline. From all the plans in the SQL plan baseline, the optimizer will select the one with the best cost in the current environment (including bind values, current statistics, parameters, etc.). The optimizer will also generate the best-cost plan that it would otherwise have used without a SQL plan baseline. However, this best-cost plan will not be used but instead added to the statement's plan history for later verification. In other words, the optimizer will use a known plan from the SQL plan baseline instead of a new and hitherto unknown plan. This guarantees no performance regression.
Let's see this plan selection process in action. First, we create a SQL plan baseline by enabling automatic plan capture and executing the query twice:
SQL> alter session set optimizer_capture_sql_plan_baselines = true;
Session altered.
SQL> var pid number
SQL> exec :pid := 100;
PL/SQL procedure successfully completed.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
9 rows selected.
SQL> select * from table(dbms_xplan.display_cursor('bfbr3zrg9d5cc', 0, 'basic note'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
EXPLAINED SQL STATEMENT:
------------------------
select p.prod_name, s.amount_sold, t.calendar_year from sales s,
products p, times t where s.prod_id = p.prod_id and s.time_id =
t.time_id and p.prod_id < :pid
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
25 rows selected.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
9 rows selected.
SQL> alter session set optimizer_capture_sql_plan_baselines = false;
Session altered.
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
We can see that a SQL plan baseline was created for the statement. Suppose the statement is hard parsed again (we do it here by flushing the shared pool). Let's turn off SQL plan management and execute the query with a different bind value:
SQL> exec :pid := 100000;
PL/SQL procedure successfully completed.
SQL> alter system flush shared_pool;
System altered.
SQL> alter session set optimizer_use_sql_plan_baselines = false;
Session altered.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
960 rows selected.
SQL> select * from table(dbms_xplan.display_cursor('bfbr3zrg9d5cc', 0, 'basic note'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
EXPLAINED SQL STATEMENT:
------------------------
select p.prod_name, s.amount_sold, t.calendar_year from sales s,
products p, times t where s.prod_id = p.prod_id and s.time_id = t.time_id and
p.prod_id < :pid
Plan hash value: 2361178149
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | PARTITION RANGE ALL| |
| 4 | TABLE ACCESS FULL | SALES |
| 5 | TABLE ACCESS FULL | TIMES |
| 6 | TABLE ACCESS FULL | PRODUCTS |
------------------------------------------
20 rows selected.
We can see that the optimizer selected a different plan because the new bind value makes the predicate less selective. Let's turn SQL plan management back on and re-execute the query with the same bind value:
SQL> alter session set optimizer_use_sql_plan_baselines = true;
Session altered.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
960 rows selected.
SQL> select * from table(dbms_xplan.display_cursor('bfbr3zrg9d5cc', 0, 'basic note'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
EXPLAINED SQL STATEMENT:
------------------------
select p.prod_name, s.amount_sold, t.calendar_year from sales s,
products p, times t where s.prod_id = p.prod_id and s.time_id =
t.time_id and p.prod_id < :pid
Plan hash value: 2787970893
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID | PRODUCTS |
| 5 | INDEX RANGE SCAN | PRODUCTS_PK |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 8 | BITMAP CONVERSION TO ROWIDS | |
| 9 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 10 | INDEX UNIQUE SCAN | TIME_PK |
| 11 | TABLE ACCESS BY INDEX ROWID | TIMES |
----------------------------------------------------------------
Note
-----
- SQL plan baseline SYS_SQL_PLAN_fcc170b0a62d0f4d used for this statement
29 rows selected.
The note at the bottom tells you that the optimizer is using the SQL plan baseline. In other words, we can see that the optimizer used an accepted plan in the SQL plan baseline in favor of a new plan. In fact, we can also check that the optimizer inserted the new plan into the statement's plan history:
SQL> select sql_text, plan_name, enabled, accepted from dba_sql_plan_baselines;
SQL_TEXT PLAN_NAME ENA ACC
---------------------------------------- ------------------------------ --- ---
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b08cbcb825 YES NO
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
select p.prod_name, s.amount_sold, t.cal SYS_SQL_PLAN_fcc170b0a62d0f4d YES YES
endar_year
from sales s, products p, times t
where s.prod_id = p.prod_id
and s.time_id = t.time_id
and p.prod_id < :pid
The 'NO' value for the accepted column implies that the new plan is in the plan history but is not available for use until it is verified to be a good plan. The optimizer will continue to use an accepted plan until new plans are verified and added to the SQL plan baseline. If there is more than one plan in the SQL plan baseline, the optimizer will use the one with the best cost under the then-current conditions (statistics, bind values, parameter settings and so on).
When you create a SQL plan baseline for a SQL statement, the SPM aware optimizer thus guarantees that no new plans will be used other than the ones in the SQL plan baseline. This prevents unexpected plan changes that sometimes lead to performance regressions.
Preventing new plans from being used is fine, but what if the new plans are in fact better? In Part 3, we will describe how new and improved plans are added to a SQL plan baseline.
Thursday, January 8, 2009
Plan regressions got you down? SQL Plan Management to the rescue!
Part 1 of 4: Creating SQL plan baselines
Do you ever experience performance regressions because an execution plan has changed for the worse? If you have, then we have an elegant solution for you in 11g called SQL Plan Management (SPM). The next four posts on our blog will cover SPM in detail. Let's begin by reviewing the primary causes for plan changes.
Execution plan changes occur due to various system changes. For example, you might have (manually or automatically) updated statistics for some objects, or changed a few optimizer-related parameters. A more dramatic change is a database upgrade (say from 10gR2 to 11g). All of these changes have the potential to cause new execution plans to be generated for many of your SQL statements. Most new plans are obviously improvements because they are tailored to the new system environment, but some might be worse leading to performance regressions. It is the latter that cause sleepless nights for many DBAs.
DBAs have several options for addressing these regressions. However, what most DBAs want is simple: plans should only change when they will result in performance gains. In other words, the optimizer should not pick bad plans, period.
This first post in our series, describes the concepts of SQL Plan Management and how to create SQL plan baselines. The second part will describe how and when these SQL plan baselines are used. The third part will discuss evolution, the process of adding new and improved plans to SQL plan baselines. Finally, the fourth part will describe user interfaces and interactions with other Oracle objects (like stored outlines).
Introduction
SQL Plan Management (SPM) allows database users to maintain stable yet optimal performance for a set of SQL statements. SPM incorporates the positive attributes of plan adaptability and plan stability, while simultaneously avoiding their shortcomings. It has two main objectives:
The plan history enables the SPM aware optimizer to determine whether the best-cost plan it has produced using the cost-based method is a brand new plan or not. A brand new plan represents a plan change that has potential to cause performance regression. For this reason, the SPM aware optimizer does not choose a brand new best-cost plan. Instead, it chooses from a set of accepted plans. An accepted plan is one that has been either verified to not cause performance regression or designated to have good performance. A set of accepted plans is called a SQL plan baseline, which represents a subset of the plan history.
A brand new plan is added to the plan history as a non-accepted plan. Later, an SPM utility verifies its performance, and keeps it as a non-accepted plan if it will cause a performance regression, or changes it to an accepted plan if it will provide a performance improvement. The plan performance verification process ensures both plan stability and plan adaptability.
The figure below shows the SMB containing the plan history for three SQL statements. Each plan history contains some accepted plans (the SQL plan baseline) and some non-accepted plans.
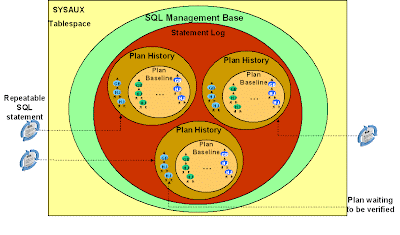
(Click on the image for a larger view.)
You can create a SQL plan baseline in several ways: using a SQL Tuning Set (STS); from the cursor cache; exporting from one database and importing into another; and automatically for every statement. Let's look at each in turn. The examples in this blog entry use the Oracle Database Sample Schemas so you can try them yourself.
Automatic plan capture will not occur for a statement if a stored outline exists for it and is enabled and the parameter use_stored_outlines is TRUE. In this case, turn on incremental capture of plans into an STS using the function capture_cursor_cache_sqlset() in the DBMS_SQLTUNE package. After you have collected the plans for your workload into the STS, manually create SQL plan baselines using the method described earlier. Then, disable the stored outlines or set use_stored_outlines to FALSE. From now on, SPM will manage your workload and stored outlines will not be used for those statements.
In this article, we have seen how to create SQL plan baselines. In the next, we will describe the SPM aware optimizer and how it uses SQL plan baselines.
Do you ever experience performance regressions because an execution plan has changed for the worse? If you have, then we have an elegant solution for you in 11g called SQL Plan Management (SPM). The next four posts on our blog will cover SPM in detail. Let's begin by reviewing the primary causes for plan changes.
Execution plan changes occur due to various system changes. For example, you might have (manually or automatically) updated statistics for some objects, or changed a few optimizer-related parameters. A more dramatic change is a database upgrade (say from 10gR2 to 11g). All of these changes have the potential to cause new execution plans to be generated for many of your SQL statements. Most new plans are obviously improvements because they are tailored to the new system environment, but some might be worse leading to performance regressions. It is the latter that cause sleepless nights for many DBAs.
DBAs have several options for addressing these regressions. However, what most DBAs want is simple: plans should only change when they will result in performance gains. In other words, the optimizer should not pick bad plans, period.
This first post in our series, describes the concepts of SQL Plan Management and how to create SQL plan baselines. The second part will describe how and when these SQL plan baselines are used. The third part will discuss evolution, the process of adding new and improved plans to SQL plan baselines. Finally, the fourth part will describe user interfaces and interactions with other Oracle objects (like stored outlines).
Introduction
SQL Plan Management (SPM) allows database users to maintain stable yet optimal performance for a set of SQL statements. SPM incorporates the positive attributes of plan adaptability and plan stability, while simultaneously avoiding their shortcomings. It has two main objectives:
- prevent performance regressions in the face of database system changes
- offer performance improvements by gracefully adapting to database system changes
The plan history enables the SPM aware optimizer to determine whether the best-cost plan it has produced using the cost-based method is a brand new plan or not. A brand new plan represents a plan change that has potential to cause performance regression. For this reason, the SPM aware optimizer does not choose a brand new best-cost plan. Instead, it chooses from a set of accepted plans. An accepted plan is one that has been either verified to not cause performance regression or designated to have good performance. A set of accepted plans is called a SQL plan baseline, which represents a subset of the plan history.
A brand new plan is added to the plan history as a non-accepted plan. Later, an SPM utility verifies its performance, and keeps it as a non-accepted plan if it will cause a performance regression, or changes it to an accepted plan if it will provide a performance improvement. The plan performance verification process ensures both plan stability and plan adaptability.
The figure below shows the SMB containing the plan history for three SQL statements. Each plan history contains some accepted plans (the SQL plan baseline) and some non-accepted plans.

(Click on the image for a larger view.)
You can create a SQL plan baseline in several ways: using a SQL Tuning Set (STS); from the cursor cache; exporting from one database and importing into another; and automatically for every statement. Let's look at each in turn. The examples in this blog entry use the Oracle Database Sample Schemas so you can try them yourself.
Creating SQL plan baselines from STS
If you are upgrading from 10gR2 or have an 11g test system, you might already have an STS containing some or all of your SQL statements. This STS might contain plans that perform satisfactorily. Let's call this STS MY_STS. You can create a SQL plan baseline from this STS as follows:
SQL> variable pls number;
SQL> exec :pls := dbms_spm.load_plans_from_sqlset(sqlset_name => 'MY_STS', -
> basic_filter => 'sql_text like ''select%p.prod_name%''');
This will create SQL plan baselines for all statements that match the specified filter.
Creating SQL plan baselines from cursor cache
You can automatically create SQL plan baselines for any cursor that is currently in the cache as follows:
SQL> exec :pls := dbms_spm.load_plans_from_cursor_cache( -
> attribute_name => 'SQL_TEXT', -
> attribute_value => 'select%p.prod_name%');
This will create SQL plan baselines for all statements whose text matches the specified string. Several overloaded variations of this function allow you to filter on other cursor attributes.
Creating SQL plan baselines using a staging table
If you already have SQL plan baselines (say on an 11g test system), you can export them to another system (a production system for instance).
First, on the test system, create a staging table and pack the SQL plan baselines you want to export:
SQL> exec dbms_spm.create_stgtab_baseline(table_name => 'MY_STGTAB', -
> table_owner => 'SH');
PL/SQL procedure successfully completed.
SQL> exec :pls := dbms_spm.pack_stgtab_baseline( -
> table_name => 'MY_STGTAB', -
> table_owner => 'SH', -
> sql_text => 'select%p.prod_name%');
This will pack all SQL plan baselines for statements that match the specified filter. The staging table, MY_STGTAB, is a regular table that you should export to the production system using Datapump Export.
On the production system, you can now unpack the staging table to create the SQL plan baselines:
SQL> exec :pls := dbms_spm.unpack_stgtab_baseline( -
> table_name => 'MY_STGTAB', -
> table_owner => 'SH', -
> sql_text => 'select%p.prod_name%');
This will unpack the staging table and create SQL plan baselines. Note that the filter for unpacking the staging table is optional and may be different than the one used during packing. This means that you can pack several SQL plan baselines into a staging table and selectively unpack only a subset of them on the target system.
Creating SQL plan baselines automatically
You can create SQL plan baselines for all repeatable statements automatically by setting the parameter optimizer_capture_sql_plan_baselines to TRUE (default is FALSE). The first plan captured for any statement is automatically accepted and becomes part of the SQL plan baseline, so enable this parameter only when you are sure that the default plans are performing well.
You can use the automatic plan capture mode when you have upgraded from a previous database version. Set optimizer_features_enable to the earlier version and execute your workload. Every repeatable statement will have its plan captured thus creating SQL plan baselines. You can reset optimizer_features_enable to its default value after you are sure that all statements in your workload have had a chance to execute.
Note that this automatic plan capture occurs only for repeatable statements, that is, statements that are executed at least twice. Statements that are only executed once will not benefit from SQL plan baselines since accepted plans are only used in subsequent hard parses.
The following example shows a plan being captured automatically when the same statement is executed twice:
SQL> alter session set optimizer_capture_sql_plan_baselines = true;
Session altered.
SQL> var pid number
SQL> exec :pid := 100;
PL/SQL procedure successfully completed.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
9 rows selected.
SQL> select p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p, times t
3 where s.prod_id = p.prod_id
4 and s.time_id = t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
--------- ----------- -------------
...
9 rows selected.
SQL> alter session set optimizer_capture_sql_plan_baselines = false;
Session altered.
Automatic plan capture will not occur for a statement if a stored outline exists for it and is enabled and the parameter use_stored_outlines is TRUE. In this case, turn on incremental capture of plans into an STS using the function capture_cursor_cache_sqlset() in the DBMS_SQLTUNE package. After you have collected the plans for your workload into the STS, manually create SQL plan baselines using the method described earlier. Then, disable the stored outlines or set use_stored_outlines to FALSE. From now on, SPM will manage your workload and stored outlines will not be used for those statements.
In this article, we have seen how to create SQL plan baselines. In the next, we will describe the SPM aware optimizer and how it uses SQL plan baselines.
Subscribe to:
Comments (Atom)